海關行政處罰數據分析報告(圖片版)上 數據處理篇
本報告旨在通過數據可視化方式,系統呈現海關行政處罰的關鍵趨勢與模式。本篇(上)聚焦于數據處理的核心環節,為后續分析奠定堅實基礎。
一、 數據來源與概述
本次分析的數據來源于公開的海關行政處罰決定書。原始數據為非結構化的文本信息,主要內容包括:處罰決定書文號、當事人信息(名稱、統一社會信用代碼等)、違法事實(行為描述、涉案貨物、貨值等)、法律依據、處罰結果(罰款金額、沒收貨物等)以及作出處罰的海關單位與日期。
二、 數據處理核心流程
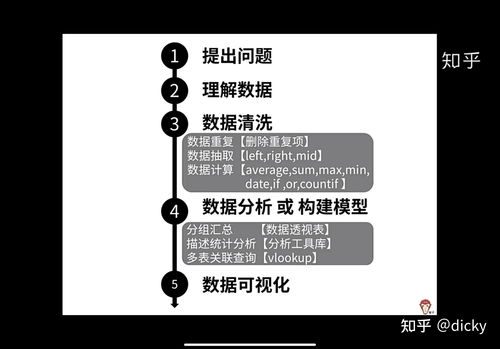
為確保分析的準確性與可視化效果,我們對原始數據進行了系統化清洗、轉換與結構化處理,主要步驟如下:
- 數據采集與解析:
- 通過技術手段批量獲取公開的處罰決定書文本。
- 利用自然語言處理(NLP)技術,結合規則匹配與模型識別,自動抽取關鍵字段信息,將非結構化文本轉化為結構化的數據記錄。
- 數據清洗與標準化:
- 字段清洗:統一日期格式(如轉換為“YYYY-MM-DD”),規范金額單位(統一為“萬元人民幣”),修正明顯的錯別字或錄入錯誤。
- 主體歸一化:對同一當事人可能存在的不同名稱表述進行歸并與標識,確保分析主體的一致性。
- 違法事實分類:根據《海關法》、《行政處罰法》及相關條例,建立違法行為分類體系(如:歸類不實、價格申報不實、侵犯知識產權、走私等),將描述性的違法事實文本映射到標準化的類別標簽。
- 地域標準化:將處罰海關單位信息映射到標準的行政區劃代碼,便于進行地理空間分析。
- 數據集成與增強:
- 將處理后的結構化數據與外部數據進行關聯,例如,將當事人統一社會信用代碼與企業工商信息(行業、注冊地、規模等)進行匹配,以豐富分析維度。
- 計算衍生指標,如“案均罰款金額”、“違法類型占比”、“月度/季度處罰數量趨勢”等。
- 數據質量校驗:
- 通過邏輯規則校驗(如罰款金額非負、處罰日期合理等)、統計描述分析以及人工抽樣復核,確保處理后數據的完整性、一致性與準確性。
- 對缺失值、異常值進行識別與合理處理(如標注、插補或排除),并記錄處理日志。
三、 處理后數據結構
經過上述流程,原始文本數據被轉化為可用于分析和可視化的結構化數據表,核心字段包括但不限于:
- 基礎信息:處罰文書號、處罰日期、作出處罰海關。
- 當事人信息:當事人名稱、統一社會信用代碼、所屬行業、注冊地區。
- 違法信息:違法行為類別(一級、二級)、具體事實摘要、涉案貨值(萬元)、主要涉案商品/物品。
- 處罰信息:罰款金額(萬元)、沒收違法所得金額(萬元)、沒收貨物情況、其他處罰措施(如警告、暫停業務等)。
- 分析標簽:季度/年度標簽、地域標簽、企業規模標簽(如根據注冊資本或行業)、風險等級標簽(基于處罰金額與頻次)等。
四、 小結
嚴謹、高效的數據處理是生成高質量數據分析報告與可視化圖表的前提。本篇完成了從原始文本到清潔、規整、多維度結構化數據的轉化,為下篇的“可視化分析與洞察”提供了可直接使用的分析底座。處理后的數據已準備好接入BI工具或編程環境,以生成直觀、深入的圖片版分析報告。
如若轉載,請注明出處:http://m.homtel.cn/product/2.html
更新時間:2026-05-18 21:20:50