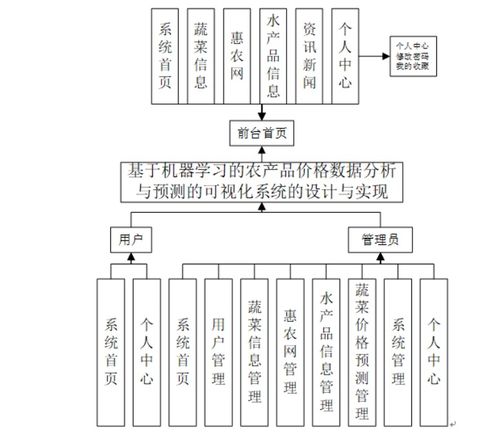
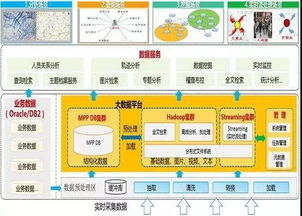
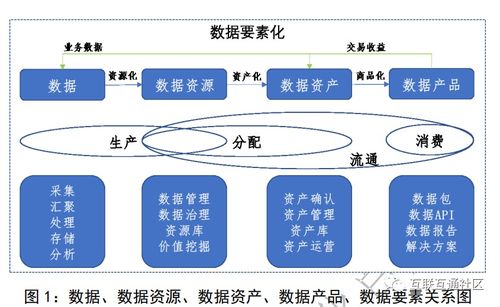
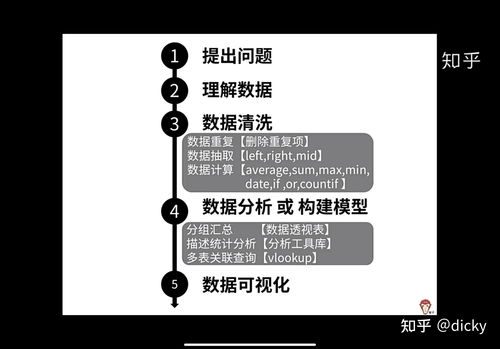
從卡片到云端 一文讀懂數據庫發展史與計算機系統服務的演進
數據庫作為計算機系統服務的核心組成部分,其發展歷程不僅是技術演進的縮影,更是驅動社會數字化轉型的關鍵力量。從早期的簡單數據管理到如今的智能云服務,數據庫的每一次飛躍都深刻重塑了我們處理信息的方式。
第一階段:萌芽與奠基(20世紀50-60年代)
在計算機誕生初期,數據處理主要依賴穿孔卡片和磁帶等物理介質,數據與程序緊密耦合,難以共享和維護。直到1960年代,隨著磁盤存儲的出現和商業應用需求的增長,數據庫的概念開始萌芽。1963年,查爾斯·巴赫曼設計了第一個通用數據庫管理系統(DBMS)IDS,奠定了導航式數據庫的基礎。這一時期的計算機系統服務主要面向大型機構,以批處理為主,服務形態單一且昂貴。
第二階段:關系型革命(20世紀70-80年代)
1970年,IBM研究員埃德加·科德發表論文,提出了關系模型,將數據組織成二維表格,并用簡單的SQL語言進行操作。這一革命性思想催生了System R、Ingres等原型系統,并在1980年代隨著Oracle、DB2、SQL Server等商業產品的崛起而普及。關系型數據庫憑借其清晰的邏輯、強大的事務處理(ACID特性)和標準化查詢語言,迅速成為企業信息系統的基石。此時的計算機系統服務開始向客戶機/服務器架構演進,數據庫作為獨立的服務層,支撐起金融、電信等關鍵行業的在線交易處理(OLTP)。
第三階段:多元化與擴展(20世紀90年代-21世紀初)
互聯網的爆發帶來了海量數據和高并發訪問的挑戰。為了應對Web應用、內容管理等新場景,對象數據庫、XML數據庫等嘗試出現。數據倉庫和聯機分析處理(OLAP)技術興起,以支持商業智能和決策分析。計算機系統服務進入分布式時代,中間件技術(如CORBA)和三層架構(表現層、邏輯層、數據層)成為標準,數據庫服務開始強調高可用性、可擴展性和安全性。
第四階段:大數據與NoSQL浪潮(21世紀初-2010年代)
社交媒體、移動設備和物聯網催生了大數據時代。傳統關系型數據庫在處理非結構化數據、橫向擴展方面遇到瓶頸,以Google的BigTable、Amazon的Dynamo為藍本,NoSQL數據庫(如MongoDB、Cassandra、Redis)應運而生。它們犧牲部分一致性,優先保證可用性和分區容錯性(CAP理論),完美契合了社交網絡、實時推薦等場景。計算機系統服務全面云化,數據庫即服務(DBaaS)模式出現,用戶無需管理底層硬件,即可按需獲取彈性、可靠的數據庫服務。
第五階段:云原生與智能化(2010年代至今)
云計算成為主流基礎設施,數據庫發展進入云原生階段。云原生數據庫(如AWS Aurora、Google Spanner、阿里云PolarDB)深度融合云計算的彈性、微服務架構和容器化部署,實現了存儲計算分離、全球分布式和秒級擴縮容。NewSQL數據庫(如TiDB、CockroachDB)試圖融合NoSQL的擴展性與SQL的強大功能。人工智能的融入使得數據庫具備自治管理、智能調優和預測分析能力。計算機系統服務已演變為一個集IaaS、PaaS、SaaS于一體的復雜生態系統,數據庫作為核心數據智能引擎,正驅動著人工智能、物聯網和邊緣計算的融合創新。
展望未來:融合與自治
數據庫的發展史,本質上是一部計算機系統服務不斷抽象、集成和智能化的歷史。多模數據庫(統一支持多種數據模型)、HTAP(混合事務/分析處理)和Serverless架構將進一步打破界限。數據庫將更加深度地與AI融合,實現更高程度的自運維、自安全和自優化,成為無處不在的智能數據服務,繼續作為數字經濟的堅實底座,賦能千行百業的創新與變革。
如若轉載,請注明出處:http://m.homtel.cn/product/6.html
更新時間:2026-05-20 17:03:07