基于MySQL的亞馬遜智能產品評論數據分析中的數據處理與分列技術
在當今數據驅動的商業環境中,亞馬遜等電商平臺的智能產品評論是洞察市場趨勢、產品表現和用戶偏好的寶貴資源。原始的評論數據往往混雜、非結構化,直接分析難度大。本文聚焦于如何利用MySQL數據庫進行高效的數據處理,特別是數據分列技術,為后續的深度分析奠定堅實基礎。
一、 數據獲取與初步觀察
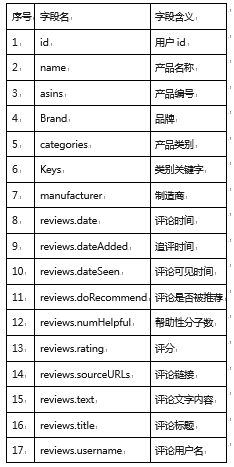
我們從公開數據集或內部渠道獲取亞馬遜智能產品(如智能音箱、智能家居設備等)的評論數據。原始數據通常以CSV或JSON格式存儲,包含但不限于以下字段:review<em>id(評論ID)、product</em>id(產品ID)、reviewer<em>id(用戶ID)、review</em>text(評論文本)、review<em>rating(評分,如1-5星)、review</em>date(評論日期)、helpful<em>votes(有用投票數)等。在導入MySQL前,需使用LOAD DATA INFILE或圖形化工具(如MySQL Workbench)將數據載入預定結構的表中。初步使用DESCRIBE table</em>name;和SELECT * FROM table_name LIMIT 10;等SQL命令觀察數據結構、類型及樣本,識別潛在問題,如缺失值、異常格式或冗余字段。
二、 核心數據處理:分列與字段解析
“分列”是數據處理中的關鍵步驟,旨在將復合字段拆分為更原子化、易于分析的獨立列。在亞馬遜評論場景中,常見分列需求包括:
1. 時間字段解析:原始review<em>date可能為“2023-05-15 14:30:00”格式。我們可以使用MySQL的日期時間函數進行分列,提取年、月、日、小時等獨立維度,便于按時間趨勢分析。
`sql
ALTER TABLE reviews ADD COLUMN reviewyear INT, ADD COLUMN reviewmonth INT;
UPDATE reviews SET reviewyear = YEAR(reviewdate), reviewmonth = MONTH(review_date);
`
2. 評論文本特征提取:review<em>text是核心非結構化數據。雖然深度文本分析(如情感分析)通常需借助Python等工具,但可在MySQL中執行基礎分列:
- 長度特征:計算評論字數或字符數,作為詳盡度的指標。
`sql
ALTER TABLE reviews ADD COLUMN textlength INT;
UPDATE reviews SET textlength = CHARLENGTH(review_text);
`
- 關鍵詞標志:使用LIKE或REGEXP創建布爾列,標記評論是否包含特定關鍵詞(如“電池壽命”、“易用性”、“bug”)。
`sql
ALTER TABLE reviews ADD COLUMN mentionsbattery BOOLEAN DEFAULT FALSE;
UPDATE reviews SET mentionsbattery = TRUE WHERE reviewtext LIKE '%電池%' OR reviewtext LIKE '%battery%';
`
3. 復合評分解析:有時原始評分可能包含在文本中,或需從其他復合字段(如“5 out of 5 stars”)提取。可使用字符串函數(如SUBSTRING<em>INDEX, REGEXP</em>SUBSTR)進行分列。
4. 用戶行為分列:helpful<em>votes字段可能隱含“總投票數”和“認為有用的票數”。若原始數據為“15/20”格式,則可分列為兩列:
`sql
ALTER TABLE reviews ADD COLUMN helpfulcount INT, ADD COLUMN totalvotes INT;
UPDATE reviews
SET helpfulcount = CAST(SUBSTRINGINDEX(helpfulvotes, '/', 1) AS UNSIGNED),
totalvotes = CAST(SUBSTRINGINDEX(helpfulvotes, '/', -1) AS UNSIGNED)
WHERE helpfulvotes LIKE '%/%';
`
三、 數據清洗與質量提升
分列前后,需進行全面的數據清洗:
- 處理缺失值:使用
COALESCE()函數為關鍵字段設置默認值,或根據業務邏輯決定刪除/插補。 - 標準化格式:確保分列后的數據格式統一,如日期為
DATE類型,數值為INT/DECIMAL類型。 - 去重與一致性檢查:通過
DISTINCT、GROUP BY結合HAVING子句識別并處理重復評論或異常記錄。 - 創建衍生列:基于分列后的基礎字段,計算衍生指標,如
helpfulness<em>ratio(有用率 = helpfulcount / total_votes),為分析提供更多維度。
四、 數據整合與索引優化
完成分列與清洗后,數據表結構更加清晰。此時,應:
- 重構表結構:考慮將大表規范化,例如將頻繁分析的字段(如產品信息、用戶 demographics 如果可用)拆分到關聯表,通過
JOIN查詢,提高靈活性。 - 添加索引:在分列后常用于查詢和連接的列(如
product<em>id,review</em>year,review_rating)上創建索引,顯著提升后續分析查詢的性能。
五、
通過MySQL強大的字符串函數、日期時間函數和DML(數據操作語言)能力,我們可以對亞馬遜智能產品評論數據執行有效的分列處理,將原始非結構化或半結構化數據轉化為整潔、多維度、適于分析的結構化格式。這一數據處理階段是后續進行趨勢分析、產品對比、用戶情感挖掘和預測建模的基石。值得注意的是,對于極復雜的文本分析,可能需要結合外部工具,但MySQL在數據預處理和基礎特征工程方面的效率與便捷性,使其成為數據分析流程中不可或缺的一環。經過精心處理的數據集將賦能企業做出更智能的產品改進與營銷決策。
如若轉載,請注明出處:http://m.homtel.cn/product/7.html
更新時間:2026-05-20 21:46:32